Pattern: Match anything
“Match anything” is one of the patterns that you can select on the Match panel. This pattern allows a field to match any text, except perhaps for certain characters that may occur in the next field. The repetition settings for the field determine how many characters the field can or must match.
This pattern is actually the first pattern in the list of patterns in RegexMagic because it is the most generic pattern. But it’s the last example in this help file because in most cases you get a more accurate and better performing regular expression by using a more specific pattern. It is very rare that you want to allow part of your regex to match truly any text. Usually there are exceptions. If you do want to use the “match anything pattern”, pay attention to the “match anything except” choice. This example illustrates two of those choices.
For this example, we’ll try to match a pair of HTML bold tags, with any text between them, but no other HTML tags between them.
- Click the New Formula button on the top toolbar to clear out all settings on the Samples, Match, and Action panels.
- On the Samples panel, paste in one new sample:
This is some <b>bold</b> text.
This one <b>also</b>.
<b>Whatever</b>.
Mixing <b>bold and <i>italic</i></b> together.
- On the Match panel, set both “begin regex match at” and “end regex match at” to “anywhere”.
- Again on the Samples panel, select the first <b> tag, and click the Mark button. This marks the first opening bold tag as field
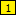 .
.
- Select the word bold adjacent to the tag you just marked, and click the Mark button to mark it as field
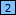 .
.
- Select the first </b tag. Click the Mark button to mark the first closing bold tag as field
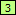 . The first sample has been marked now:
. The first sample has been marked now: This is some <b>bold</b> text.
This one <b>also</b>.
<b>Whatever</b>.
Mixing <b>bold and <i>italic</i></b> together.
- On the Match panel, use the “select field” drop-down list to select field . Since we only marked one piece of text for this field that doesn’t fit any particular pattern, RegexMagic selected the “literal text” pattern for this field, making it match the word “bold” that we marked.
- In the “pattern to match field” drop-down list, select “match anything”.
- In the “match anything except” drop-down list, select “first character of the next field”. The next field is field , which matches the literal text </b>. Thus, excluding the first character of the next field makes field match any character except an opening angle bracket. This meets our requirement of excluding nested HTML tags.

- In the list of fields in the regular expression at the top of the Match panel, next to field , enter 1 under “repeat this field” and tick the “unlimited” checkbox. Since we only marked one sample that is 4 characters long, RegexMagic set this field to allow exactly 4 characters. Now we’ve set it to allow any number of characters.
- Use the “select field” drop-down list to select field .
- Turn on “case insensitive” among the options for the literal text pattern for this field.
- Repeat the previous two steps for field .
- On the Regex panel, select “C# (.NET 2.0–7.0)” as your application, turn off free-spacing, and turn off mode modifiers. Click the Generate button, and you’ll get this regular expression:
<b>[^\n\r<]+</b>
Required options: Case insensitive.
Unused options: Exact spacing; Dot doesn’t match line breaks; ^$ don’t match at line breaks; Numbered capture.
- The Samples panel now confirms our regular expression matches a pair of bold tags with any text between them, except HTML tags:
This is some <b>bold</b> text.
This one <b>also</b>.
<b>Whatever</b>.
Mixing <b>bold and <i>italic</i></b> together.
With a few simple changes, we can generate another regex that matches a pair of HTML bold tags that allows any text in between, including any HTML tags except the closing bold tag.
- On the Match panel, set “how to repeat this field” to “as few times as possible” for field . This is necessary to ensure that the regex match will end at the first closing tag after the opening tag rather than at the last closing tag in the file.
- Use the “select field” drop-down list to select field if not already selected.
- In the “match anything except” drop-down list, select “text matched by the next field”.
- Regenerate the regex and you’ll get:
<b>(?>.+?</b>)
Required options: Case insensitive; Dot doesn’t match line breaks.
Unused options: Exact spacing; ^$ don’t match at line breaks; Numbered capture.
- The Samples panel now confirms our regular expression matches a pair of bold tags with any text between them, including HTML tags, except </b>:
This is some <b>bold</b> text.
This one <b>also</b>.
<b>Whatever</b>.
Mixing <b>bold and <i>italic</i></b> together.
Reference