Pattern: Unicode characters
“Unicode characters” is one of the patterns that you can select on the Match panel. Use this pattern to restrict a field to a certain set of Unicode characters. The repetition settings for the field determine how many characters the field can or must match.
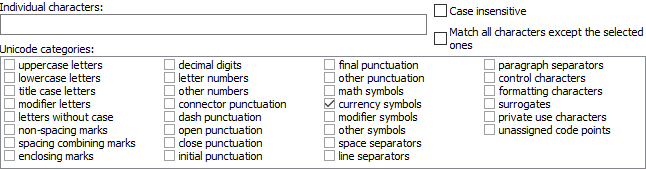
Individual Characters
Type in a list of characters that you want to allow in this field.
You can only type in characters that don't fit any of the categories that you've turned on below.
Case Insensitive
Turn on to allow the field to match both the lowercase and uppercase variants of all letters that you typed in as individual characters. When on, the lowercase and uppercase letter groups will also match both variants, even if you turned on only one of them.
Turn off to make the field respect the case of the individual characters you've typed in.
Match All Characters Except The Selected Ones
Turn on to make the field match any character except those that you specified.
Turn off to make the field match only those characters that you specified.
Unicode Categories
Turn on one or more Unicode categories to have the field include all characters that are in one of the selected categories. Turning on categories removes all characters with the selected categories from the list of individual characters above.
Turn off Unicode categories if you don't want the field to include any characters from certain categories, except for those characters that you have entered as individual characters. Turning off a Unicode category puts back any individual characters that were removed by turning that category on.
- lowercase letters: lowercase letters that have uppercase variants.
- uppercase letters: uppercase letters that have lowercase variants.
- title case letters: letters that appear at the start of a word when only the first letter of the word is capitalized.
- modifier letters: special characters that are used like a letter.
- other letter: letters or ideographs that do not have lowercase and uppercase variants.
- non-spacing marks: characters intended to be combined with other characters without taking up extra space (e.g. accents, umlauts, etc.).
- spacing combining marks: a character intended to be combined with another character that takes up extra space (vowel signs in many Eastern languages).
- enclosing marks: a character that encloses the character is is combined with (circle, square, keycap, etc.).
- decimal digits: digits 0 through 9 in all scripts except ideographic scripts.
- letter numbers: numbers that look like letters, such as a Roman numerals.
- other numbers: superscript or subscript digits, and numbers that are not digit 0..9 (excluding numbers from ideographic scripts).
- dash punctuation: all kinds of hyphens and dashes.
- open punctuation: all kinds of opening brackets.
- close punctuation: all kinds of closing brackets.
- initial punctuation: all kinds of opening quotes.
- final punctuation: all kinds of closing quotes.
- connector punctuation: punctuation characters such as underscores that connects words.
- other punctuation: all kinds of punctuation characters that are not dashes, brackets, quotes, or connectors.
- math symbols: all mathematical symbols.
- currency symbols: all currency signs.
- modifier symbols: combining characters (mark) as full characters on their own.
- other symbols: various symbols that are not math symbols, currency signs, or combining characters.
- space separators: a whitespace character that is invisible, but does take up space.
- line separators: line separator character U+2028.
- paragraph separators: paragraph separator character U+2029.
- control characters: ASCII 0x00..0x1F and Latin-1 0x80..0x9F control characters.
- formatting characters: invisible formatting indicators.
- private use characters: all code points reserved for private use.
- surrogates: one half of a surrogate pair in UTF-16 encoding.
- unassigned: all code points to which no characters have been assigned.
Examples