Matching Comments in Java Code
This example shows how you can generate a regular expression to match comments as used in Java and other programming languages. First we create a regex that matches single-line comments. These start with // and run until the end of the line.
- Click the New Formula button on the top toolbar to clear out all settings on the Samples, Match, and Action panels.
- On the Samples panel, paste in one new sample:
// Single-line comment
/* Multi-line comments
can span multiple lines */
/* Multi-line comments
/* cannot be nested // at all */
Not a comment
/* This comment */ // split in two
// Single-line comments // cannot be /* nested */
/** Documentation comment **/
// Done!
- Set the subject scope to “whole sample”.
- Select the // at the start of the sample and click the Mark button. RegexMagic adds field
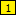 which matches // literally.
which matches // literally.
- Select the remainder of the line. Begin your selection immediately after the // so the space is included. End your selection before the line break at the end of the line.
- Click the Mark button again. RegexMagic adds field
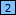 . It also literally matches the text we just marked.
. It also literally matches the text we just marked.
- We’ll need to change field to match anything until the end of the line. On the Match panel, set “pattern to match field” to “match anything”. Then set “match anything except” to “nothing”.
- Make sure “can span across lines is turned off”. It should be by default because RegexMagic sees that the sample we marked for field does not include any line breaks.
- Set the left hand “repeat this field” spinner for field to zero and tick the “unlimited” checkbox to allow field to match any number of characters.
- On the Regex panel, select “Java 8” as your application, turn off free-spacing, and turn off mode modifiers. Click the Generate button, and you’ll get this regular expression:
//.*
Required options: Dot doesn’t match line breaks; Default line breaks.
Unused options: Case sensitive; Exact spacing; ^$ don’t match at line breaks.
- The Samples panel now shows that our regex matches all single-line comments:
// Single-line comment
/* Multi-line comments
can span multiple lines */
/* Multi-line comments
/* cannot be nested // at all */
Not a comment
/* This comment */ // split in two
// Single-line comments // cannot be /* nested */
/** Documentation comment **/
// Done!
Matching Multi-Line Comments Too
The first example matches only single-line comments. It totally ignores multi-line comments. So it does match any // that occurs within a multi-line comments as a single-line comment. We can extend our regular expression to properly deal with both types of comments.
- On the Samples panel, select the first /* and click the Mark button. Because we left a gap (the line break) between field and the newly marked field, RegexMagic treats the newly marked /* as the start of a new alternative that the generated regular expression should be able to match independently from the previous set of fields. This is correct. We want our regex to be able to separately match single-line and multi-line comments. So RegexMagic adds a new alternation field to hold our two alternatives. It adds a new sequence field that holds the original two fields that match the single-line comment. These are now numbered
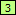 and
and 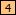 . The second alternative under field is the newly added field
. The second alternative under field is the newly added field 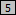 which matches the /* we marked literally.
which matches the /* we marked literally.
- Select all the text between the /* we just marked and the */ that follows it, including the spaces right next to these. Click the Mark button. Because we marked this immediately adjacent to what we marked for the last field, RegexMagic treats it as a continuation of the same alternative. Again correct. We’re still building the alternative for the multi-line comment. RegexMagic changes field to be a sequence field with field
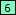 being the old field matching the /* and field
being the old field matching the /* and field 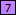 matching the two lines of text we just marked. We’ll adjust field soon.
matching the two lines of text we just marked. We’ll adjust field soon.
- Select the */ and click the Mark button. RegexMagic adds field
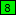 to the sequence. It matches */ literally.
to the sequence. It matches */ literally.
- On the Match panel, select field in the “select field” drop-down list.
- Set “pattern to match field” to “match anything”.
- Set “match anything except” to “text matched by the next field”. This ensures that field can never match the text matched by field . The comment must end at the first */. This would be important if we added more fields to the sequence after field to match something that follows the comment. If that something is missing, we don’t want the regex engine to try to expand the comment until the next */in the file.
- Set the left hand “repeat this field” spinner for field to zero and tick the “unlimited” checkbox to allow it to match any number of characters.
- Set “how to repeat this field” to “as few times as possible”. We have to do this so that field stops before the first */. RegexMagic will refuse to generate the regex if we don’t select “as few times as possible” for a field that has “match anything except” set to “text matched by the next field”.
- Click the Generate button on the Regex panel again and you’ll get:
//.*|/\*(?>(?s:.)*?\*/)
Required options: Dot doesn’t match line breaks; Default line breaks.
Unused options: Case sensitive; Exact spacing; ^$ don’t match at line breaks.
- The Samples panel now shows that our regex matches all single-line and multi-line comments:
// Single-line comment
/* Multi-line comments
can span multiple lines */
/* Multi-line comments
/* cannot be nested // at all */
Not a comment
/* This comment */ // split in two
// Single-line comments // cannot be /* nested */
/** Documentation comment **/
// Done!
Matching Only Multi-Line Comments
If you don’t have any single-line comments to deal with, you can easily remove that part from the regular expression.
- Click on the colored rectangle for field to make the field buttons work on that field.
- Click the Delete List of Fields button. It’s glyph will show
 to indicate that it deletes sequence field along with fields and that the sequence consists of.
to indicate that it deletes sequence field along with fields and that the sequence consists of.
This is all we really need to do. But it leaves some unnecessary fields. This doesn’t impact the generated regular expression. But it leaves clutter on the Match panel.
- Select field .
- Click the Delete One Field button
 to delete field .
to delete field .
- We now have a new field that we don’t need either. Click the Delete One Field button again.
- Click the Generate button on the Regex panel and you’ll get:
/\*(?>.*?\*/)
Required options: Dot matches line breaks; Default line breaks.
Unused options: Case sensitive; Exact spacing; ^$ don’t match at line breaks.
- The Samples panel now shows that our regex matches only multi-line comments:
// Single-line comment
/* Multi-line comments
can span multiple lines */
/* Multi-line comments
/* cannot be nested // at all */
Not a comment
/* This comment */ // split in two
// Single-line comments // cannot be /* nested */
/** Documentation comment **/
// Done!
If you wanted to create this regex from scratch, you could proceed as follows after pasting in the sample text:
- On the Samples panel, select the first /* and click the Mark button. RegexMagic adds field which matches the /* we marked literally.
- Select all the text between the /* we just marked and the */ that follows it, including the spaces right next to these. Click the Mark button. RegexMagic adds field matching the two lines of text we just marked. We’ll adjust field soon.
- Select the */ and click the Mark button. RegexMagic adds field to the sequence. It matches */ literally.
- On the Match panel, select field in the “select field” drop-down list.
- Set “pattern to match field” to “match anything”.
- Set “match anything except” to “text matched by the next field”. This ensures that field can never match the text matched by field . The comment must end at the first */. This would be important if we added more fields after field to match something that follows the comment. If that something is missing, we don’t want the regex engine to try to expand the comment until the next */in the file.
- Set the left hand “repeat this field” spinner for field to zero and tick the “unlimited” checkbox to allow it to match any number of characters.
- Set “how to repeat this field” to “as few times as possible”. We have to do this so that field stops before the first */. RegexMagic will refuse to generate the regex if we don’t select “as few times as possible” for a field that has “match anything except” set to “text matched by the next field”.
- Click the Generate button on the Regex panel and you’ll get exactly the same regular expression:
/\*(?>.*?\*/)
Required options: Dot matches line breaks; Default line breaks.
Unused options: Case sensitive; Exact spacing; ^$ don’t match at line breaks.
Related Examples
Reference